# [Kafka Connect/Debezium] SMT 란?
SMT는 Single Message Transformation의 약자이다.
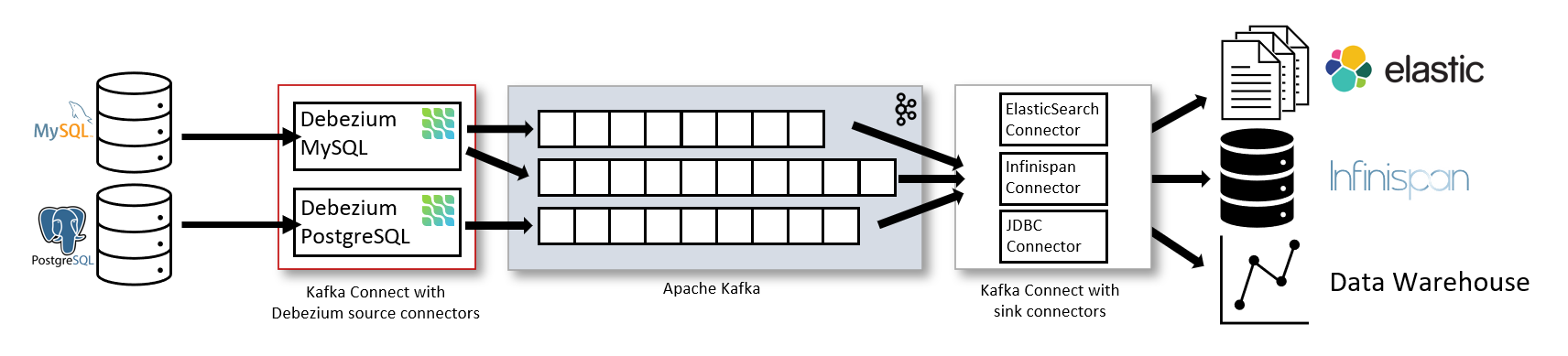
Kafka Connect에 대해서 복기해보자.
여러 데이터베이스로부터 데이터를 추출하여 Kafka topic에 넣고
Kafka topic에 있는 데이터를 다른 데이터 소스에 전달하기 위해 만들어졌다.
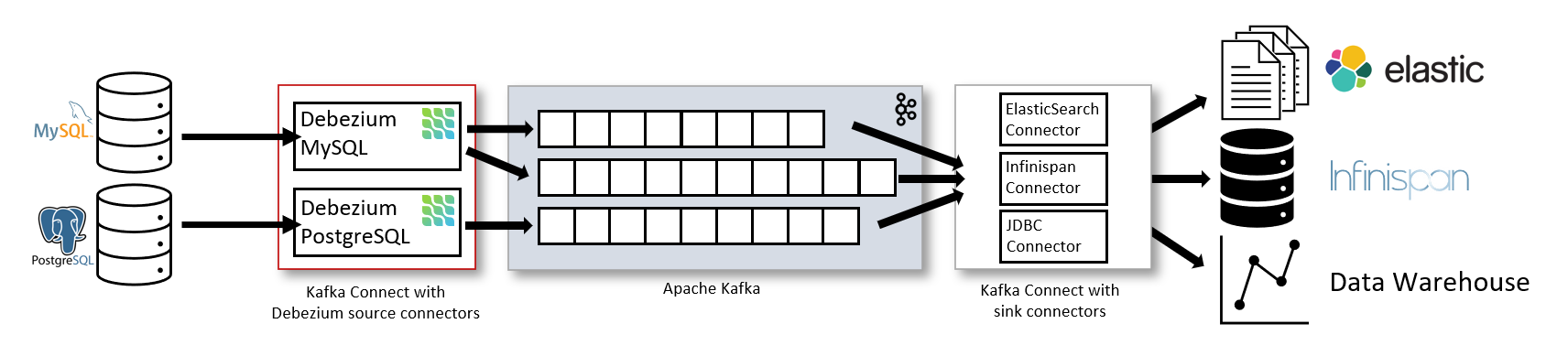
즉, 다양한 Database로부터 메세지를 생산하여
메세지들이 Kafka topic에 저장하고
다양한 데이터 소스들에게 메시지를 소비하는 것이다.
근데 debezium으로 메세지를 만들어 본 사람은 알겠지만
row 한 줄 당 메세지 한 개이다.
그리고 그 메세지는 매우 많은 정보가 들어가 있으며 그만큼 크기가 크다.
예시로 PostgreSQL Debezium에서 생성된 기본 메세지 형식을 보자.
{
"schema": {
...
},
"payload": {
"before": null,
"after": {
"id": 2,
"product": "candle",
"price": 13000,
"ins_timestamp": 1635084000213
},
"source": {
"version": "1.3.1.Final",
"connector": "postgresql",
"name": "pg_test",
"ts_ms": 1635052376362,
"snapshot": "last",
"db": "test",
"schema": "public",
"table": "t_market",
"txId": 113669095,
"lsn": 905751868160,
"xmin": null
},
"op": "r",
"ts_ms": 1635052376362,
"transaction": null
}
}schema 부분은 너무 내용이 많아 생략했고
payload 부분을 보면 before과 after로 나뉘어져 있는 것을 볼 수 있다.
그리고 해당 소스에 대한 정보가 들어가 있다.
row 한 줄마다 데이터의 before 정보와 소스 정보가 모두 들어간다고 보면 된다.
그리고 해당 정보에 대한 스키마도 모두 포함된다.
참고로 해당 메세지는 insert 동작으로 before는 null임을 알 수 있다.
그렇다면 SMT를 적용한 메세지 형식을 알아보자.
우선, SMT를 적용할 경우 다음 transform을 추가해주면 된다.
(참고로 mongodb는 다른 transform type을 사용해야 한다.)
"transforms": "unwrap",
"transforms.unwrap.type":"io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones":false,
"transforms.unwrap.delete.handling.mode":"rewrite",
"transforms.unwrap.add.fields":"op,schema"
위의 설정들은
debezium 공식문서(https://debezium.io/documentation/reference/transformations/event-flattening.html)
에서 확인하면 되고...
이렇게 SMT로 변환하도록 추가한 뒤, 메세지 형식은 다음과 같이 변경된다.
# insert
{
"schema": {
...
},
"payload": {
"id": 3,
"product": "mask",
"price": 1500,
"ins_timestamp": 1635086072124,
"__op": "c",
"__schema": "public",
"__deleted": "false"
}
}
# update
{
"schema": {
...
},
"payload": {
"id": 3,
"product": "mask",
"price": 1490,
"ins_timestamp": 1635086072124,
"__op": "u",
"__schema": "public",
"__deleted": "false"
}
}
# delete
{
"schema": {
...
},
"payload": {
"id": 3,
"product": null,
"price": null,
"ins_timestamp": null,
"__op": "d",
"__schema": "public",
"__deleted": "true"
}
}
null메세지가 훨씬 간결해지고
before 값이 없어지고 after 값만 나오는 것을 확인할 수 있다.
그리고 소스 정보도 위의 설정에서 명시한 내용만 나오도록 변형했다.
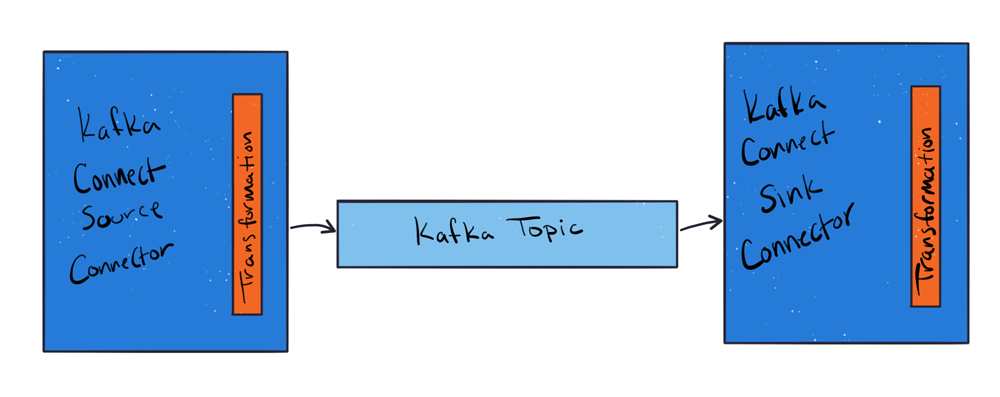
이처럼 kafka topic에 메세지를 넣기 전
transformation을 이용하여 메세지를 변형하여
필요한 정보만 kafka topic에 넣도록 하여
메세지 크기를 줄일 수 있다.
transform은 SMT 말고도 더 다른 기능들도 있다.
저장되고자 하는 kafka topic을 임의로 설정한다든지
특정 데이터를 필터링 한다든지
Debezium이 릴리즈 되면서
점점 다양한 기능들이 추가되고 있는것 같다.
그런 기능들을 조사 및 연구해서 사용하면
좀 더 편리하게 원하는 대로 데이터 파이프라인을 구축할 수 있을 것이다.

To be continued.........
Made by 꿩
'CDC > Kafka Connect' 카테고리의 다른 글
| Kafka Connect 설정 (0) | 2021.01.09 |
|---|---|
| Kafka Connect란? (0) | 2021.01.09 |